ArrayList vs LinkedList: 언제 무엇을 써야하나 (+O(1) 착각 5가지)
두가지의 자료구조 모두 List 인터페이스를 구현하지만,
실제 성능과 사용하는데 있어서의 감각은 꽤나 차이가 있습니다..
그러면 "어떤상황에서 무엇을 쓰느냐"를 판단할 수 있도록
핵심적인 차이, 자주 하는 오해, 상황별 선택 기준, 그리고 벤치마크에 관한 예제를
다음과 같이 모아 봤습니다.
시간복잡도 오해 (O(1) 착각 5가지)
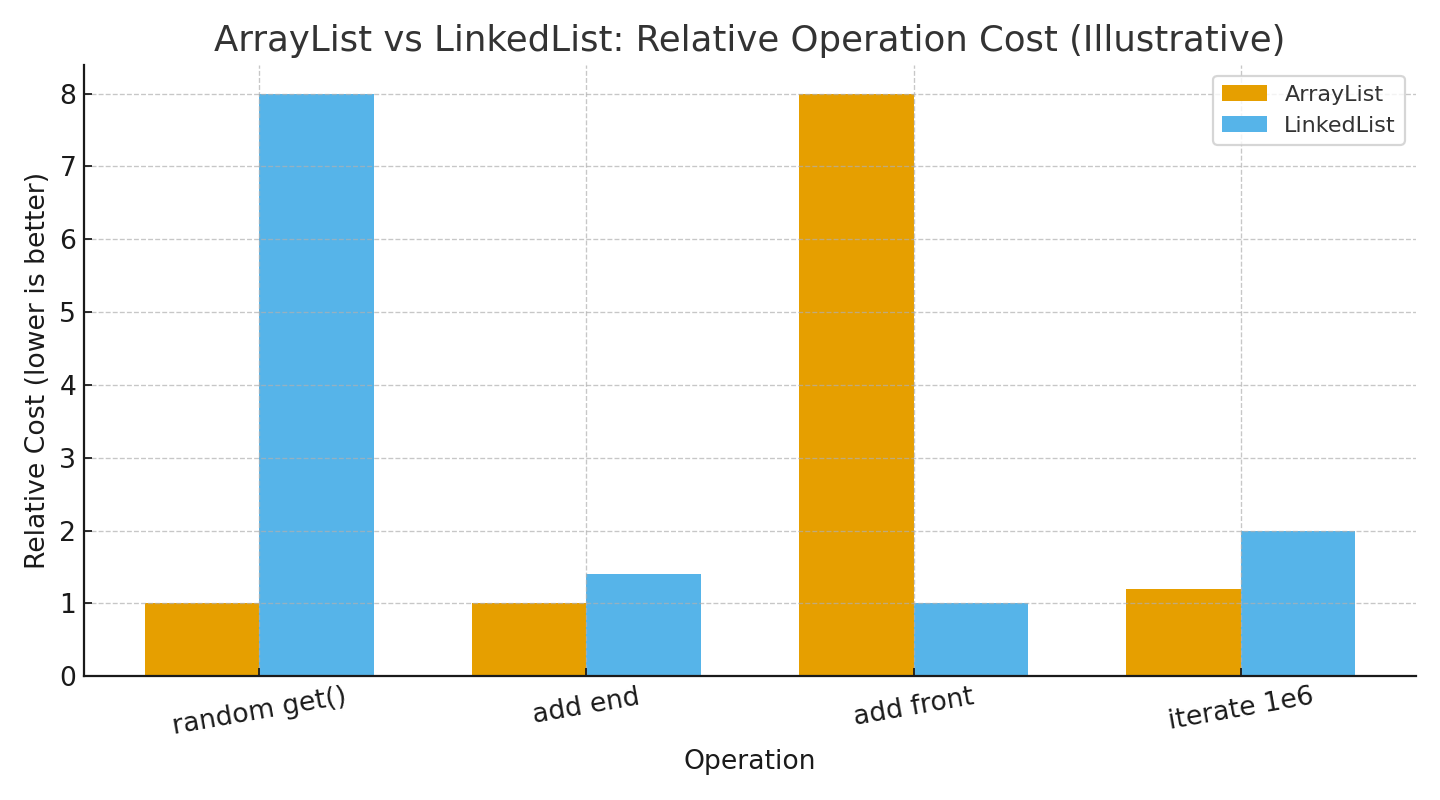
LinkedList.get(i)는 O(1)이다?
중간 노드로 가려면 앞/뒤에서 순회가 필요해 O(n)입니다. 인덱스러의 접근이 잦으면 불리합니다.ArrayList.add(e)는 늘 O(n)이다?
평균(암ortized) O(1)입니다. 버퍼가 가득 찰 때만 재할당/복사가 발생합니다.- LinkedList는 삽입이 항상 빠르다?
삽입 자체는 O(1)이 맞지만, “삽입 위치까지 도달”하는 비용이 큽니다(접근 O(n) + 삽입 O(1)). contains는 둘 다 빠르다?
정렬/해시 전제가 없다면 대부분 O(n)입니다. 검색이 잦다면 다른 구조를 고려하세요.- 순회 성능은 비슷하다?
연속 메모리를 순차 접근하는ArrayList가 캐시 적중률 덕에 유리한 경우가 많습니다.
시나리오별 선택
- 랜덤 인덱스 접근이 많다 →
ArrayList - 주로 끝에 추가 →
ArrayList(평균 O(1)) - 앞쪽 삽입/삭제가 잦다 →
LinkedList(단, 위치 탐색 비용 고려) - 큰 데이터를 길게 순회 → 보통
ArrayList가 유리 - 중간 삽입/삭제 빈번 + 접근 패턴 불명 → 소규모 벤치로 체감 후 결정
벤치마크 코드
JMH 스켈레톤
// build.gradle
// dependencies {
// implementation "org.openjdk.jmh:jmh-core:1.37"
// annotationProcessor "org.openjdk.jmh:jmh-generator-annprocess:1.37"
// }
// 실행: ./gradlew jmh
import org.openjdk.jmh.annotations.*;
import java.util.*;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 3, time = 500, timeUnit = TimeUnit.MILLISECONDS)
@Measurement(iterations = 5, time = 500, timeUnit = TimeUnit.MILLISECONDS)
@Fork(1)
@State(Scope.Thread)
public class ListBench {
@Param({"1000","100000"})
int size;
List<Integer> arrayList;
List<Integer> linkedList;
@Setup(Level.Iteration)
public void setup() {
arrayList = new ArrayList<>(size);
linkedList = new LinkedList<>();
for (int i=0;i<size;i++) { arrayList.add(i); linkedList.add(i); }
}
@Benchmark
public int arrayList_get_mid() { return arrayList.get(size/2); }
@Benchmark
public int linkedList_get_mid() { return linkedList.get(size/2); }
@Benchmark
public boolean arrayList_add_end() { return arrayList.add(-1); }
@Benchmark
public void linkedList_add_front() { linkedList.add(0, -1); }
}
루프 기반 빠른 점검
long t0 = System.nanoTime();
for (int i=0;i<N;i++) {
list.get(i % list.size());
}
long t1 = System.nanoTime();
double nsPerOp = (t1 - t0) / (double) N;
System.out.println("get loop ns/op ≈ " + nsPerOp);
요약
ArrayList는 인덱스 접근/순회/끝 삽입에 적합합니다.LinkedList는 앞쪽 삽입/삭제 자체는 빠르지만, 지점에 도달하는 비용이 변수 될 수 입니다.- 애매하면 작은 데이터셋으로 벤치 후 결정하세요.그리면 코드와 데이터가 답을 줍니다.
FAQ
Q1. 데이터가 큰데 LinkedList가 더 나을까요?
A. 접근 패턴이 핵심입니다. 인덱스 접근이 잦다면 ArrayList가 보통 더 빠릅니다.
Q2. ArrayList의 재할당 비용이 부담됩니다. 대안이 있나요?
A. 대략적인 크기를 안다면 초기 용량을 잡거나, 배치 추가 전에 ensureCapacity()를 고려하세요.
👉 1편: ArrayList vs LinkedList: 언제 무엇을 쓰나 (+O(1) 착각 5가지)
👉 2편: 제네릭 와일드카드 완전정복(PECS 암기팁 포함)
👉 3편: Stream API: for→stream 리팩터링 10가지(성능/가독 균형)
👉 4편: Optional.orElse vs orElseGet 차이와 NPE 방지
👉 5편: java.time 제대로 쓰기(타임존/포맷 실수 7가지)
👉 6편: Java Record vs Lombok DTO 선택 기준
👉 7편: NIO.2로 폴더 스캔/감시 구현(FileVisitor/WatchService)
👉 8편: ExecutorService 스레드풀 사이즈/큐 전략
'Java & Spring' 카테고리의 다른 글
| Java Record vs Lombok DTO 선택 기준: 언제 무엇을 쓸까 (0) | 2025.09.28 |
|---|---|
| java.time 제대로 쓰기: 타임존/포맷 실수 7가지와 안전한 사용법 (0) | 2025.09.28 |
| Optional.orElse vs orElseGet 차이와 NPE 방지: 실무 규칙 7가지 (0) | 2025.09.28 |
| Stream API: for→stream 리팩터링 10가지(성능/가독 균형) (0) | 2025.09.28 |
| 제네릭 와일드카드 완벽 마스터: PECS(Producer Extends, Consumer Super) 암기팁 (0) | 2025.09.28 |



