API 로그 추적과 모니터링 — APM으로 성능 시각화하기 실무 가이드
REST API를 설계하고 배포했다면, 이제는 서비스가 “어떻게 동작하는가”를 관찰할 차례입니다.
코드는 완벽할 수 없습니다. 하지만 로그와 모니터링이 있다면, 문제를 빠르게 찾고 개선할 수 있습니다.
이번 글에서는 API의 흐름을 추적하고, APM(Application Performance Monitoring) 도구를 활용해 서버 성능을 시각화하는 실무 방법을 정리했습니다.

1. 로그와 모니터링의 차이
많은 초보 개발자들이 “로그”와 “모니터링”을 혼동합니다.
두 개념은 목적이 다릅니다.
- 로그(Log): 코드 실행 과정의 세부 기록 (무엇이, 언제, 어디서 일어났는가)
- 모니터링(Monitoring): 시스템의 상태와 성능 지표 관찰 (얼마나 빠르고 안정적인가)
즉, 로그는 사건 중심(Event-based), 모니터링은 상태 중심(State-based)입니다.
이 둘을 함께 사용해야 서비스의 전반적인 흐름을 제대로 볼 수 있습니다.
2. 분산 로그 추적(Distributed Tracing)이란?
하나의 요청이 여러 마이크로서비스를 거치는 환경에서는 “어디서 지연이 발생했는가”를 찾기가 어렵습니다.
이때 사용하는 개념이 분산 로그 추적(Distributed Tracing)입니다.
[사용자 요청] → [API Gateway] → [User Service] → [Order Service] → [DB]
각 단계에서 동일한 Trace ID를 전달하면, 한 요청의 전체 흐름을 시각적으로 추적할 수 있습니다.
💡 대표 도구: Zipkin, Jaeger, Elastic APM 이들은 요청별 트레이스 그래프를 생성하여 API 호출 간 지연을 한눈에 보여줍니다.
3. Trace ID를 활용한 실무 로그 구성
Spring Boot에서 Mapped Diagnostic Context(MDC)를 사용하면 각 요청에 고유한 Trace ID를 자동으로 포함할 수 있습니다.
@Component
public class LoggingFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
String traceId = UUID.randomUUID().toString();
MDC.put("traceId", traceId);
try {
chain.doFilter(request, response);
} finally {
MDC.remove("traceId");
}
}
}
이후 logback.xml에 Trace ID를 포함시킵니다.
<pattern>[%d{HH:mm:ss.SSS}] [%X{traceId}] %-5level %logger{36} - %msg%n</pattern>
💬 이렇게 하면, 한 요청 전체의 로그를 Trace ID로 검색해 API 경로별 수행 시간을 추적할 수 있습니다.
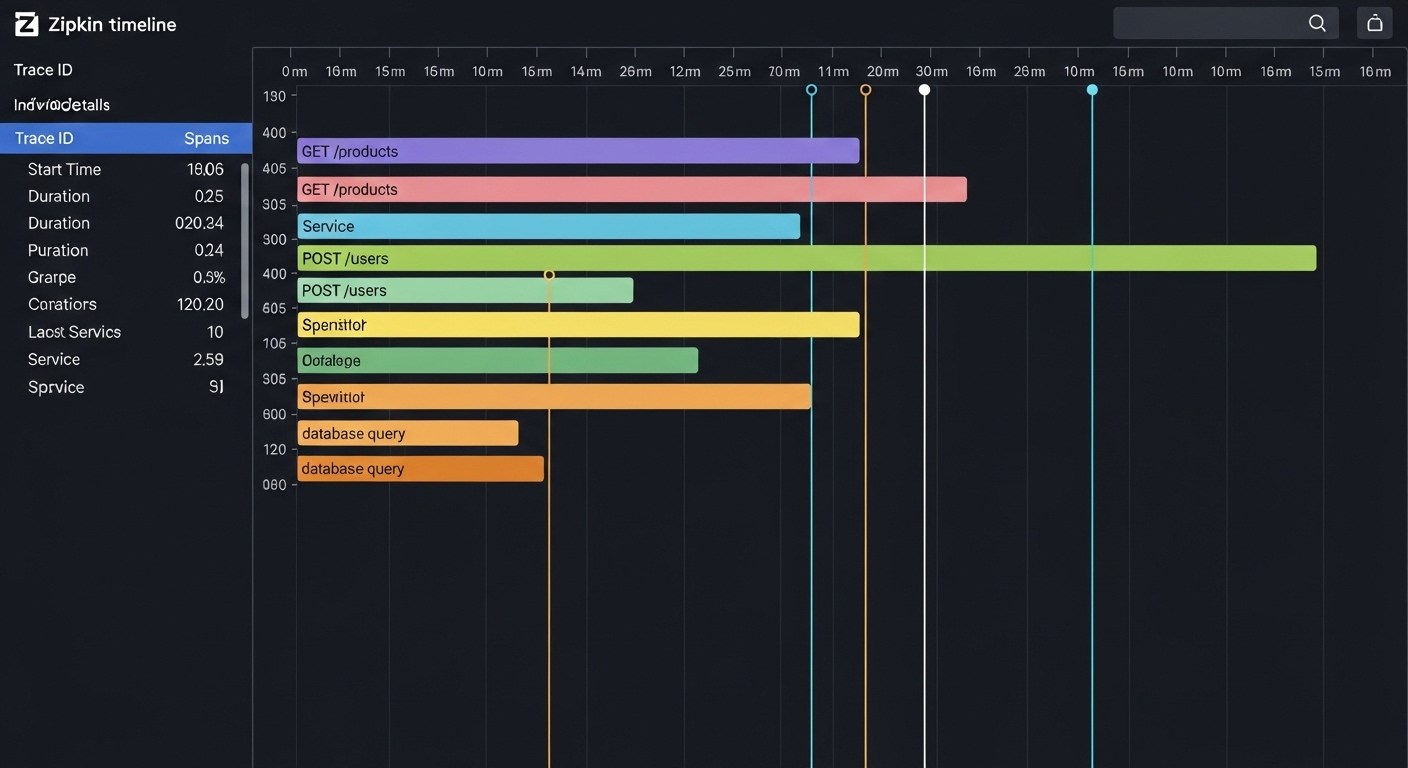
4. Zipkin으로 트레이스 시각화하기
Zipkin은 Spring Cloud Sleuth와 함께 사용되는 오픈소스 APM 도구입니다.
요청 간 호출 관계를 “Span” 단위로 시각화하여 지연이 발생한 구간을 한눈에 보여줍니다.
💡 설정 요약:
1️⃣ dependency 추가org.springframework.cloud:spring-cloud-starter-zipkin
2️⃣ application.yml 설정
spring:
zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1.0
Zipkin 서버를 실행한 후 브라우저에서 http://localhost:9411 접속하면 요청별 트레이스가 시간축 그래프로 표시됩니다.
💬 예시:
/api/orders 요청이 2초 지연된다면, Zipkin은 어느 서비스(예: PaymentService)에서 병목이 발생했는지 시각적으로 보여줍니다.
5. APM(Application Performance Monitoring) 도입 이유
단순 로그만으로는 “시스템 전체의 성능”을 파악하기 어렵습니다.
APM은 CPU, 메모리, DB 쿼리 시간, 외부 API 호출, GC 등 시스템의 모든 동작을 통합적으로 관찰합니다.
💡 대표 솔루션:
- Elastic APM (무료, Kibana 통합) - New Relic (상용) - Datadog (클라우드 기반) - Pinpoint (국산 오픈소스)
각각의 트랜잭션별 응답 시간, DB 쿼리 분석, 에러율 등을 자동 수집하여 실시간 대시보드로 제공합니다.
6. Spring Boot에 APM 연동하기 (Elastic APM 예시)
Elastic APM Agent를 설치하면 Spring Boot 애플리케이션의 모든 요청을 자동 추적할 수 있습니다.
# 1. Elastic APM Java Agent 다운로드
java -javaagent:/apm/elastic-apm-agent.jar \
-Delastic.apm.server_urls=http://localhost:8200 \
-Delastic.apm.service_name=my-api \
-Delastic.apm.application_packages=com.example \
-jar my-api.jar
💬 실행 후 Kibana의 “APM” 메뉴에서 서비스별 응답시간, 에러 트렌드, 트랜잭션 분포를 시각적으로 확인할 수 있습니다.
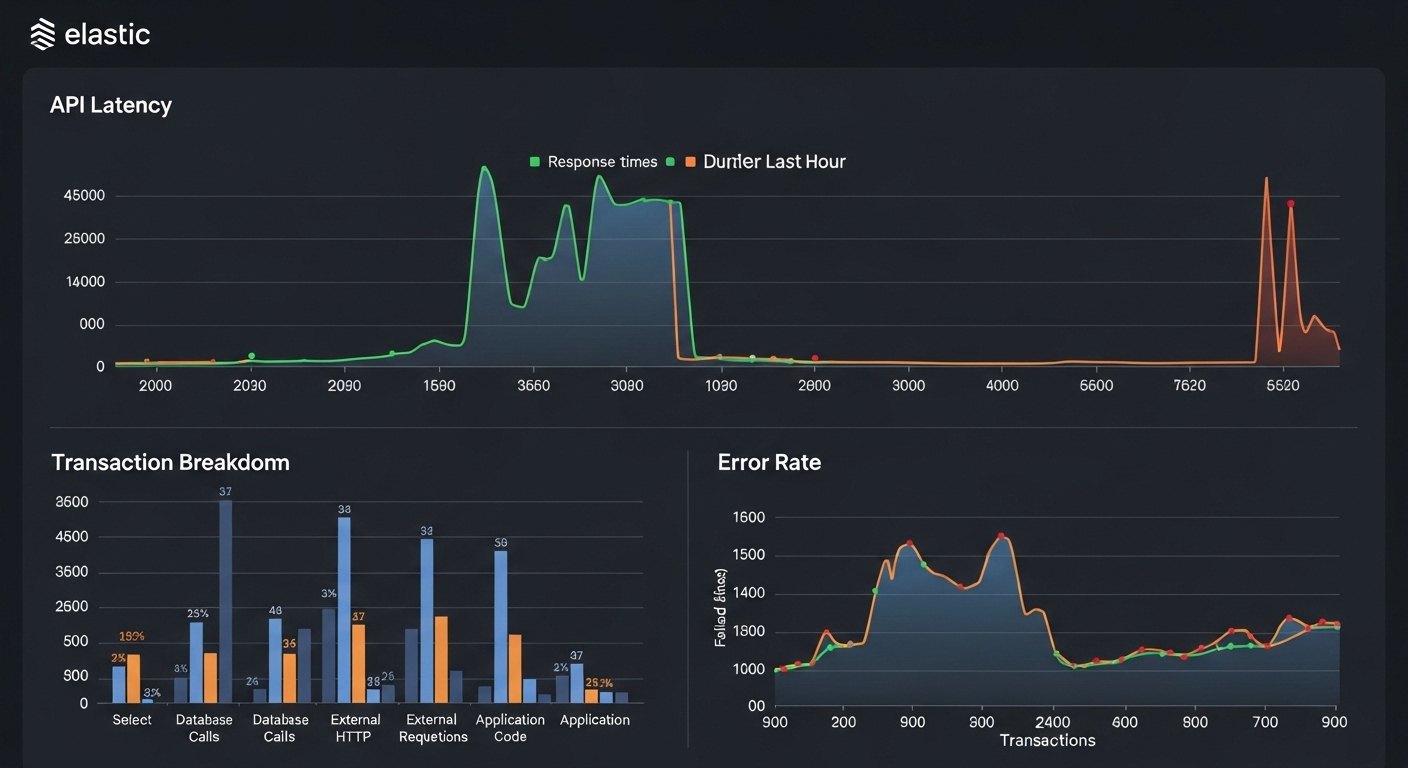
7. Prometheus + Grafana로 서버 성능 모니터링
Prometheus는 시계열(time-series) 기반의 메트릭 수집 도구이며, Grafana는 이를 시각화하는 대시보드 도구입니다.
Spring Boot에서는 Micrometer를 통해 Prometheus와 쉽게 연동할 수 있습니다.
# build.gradle
implementation 'io.micrometer:micrometer-registry-prometheus'
이후 /actuator/prometheus 엔드포인트를 열면 HikariCP, JVM, HTTP 요청 시간 등 모든 메트릭이 노출됩니다.
Grafana에서 Prometheus를 데이터소스로 연결하면 API 응답속도, 에러율, DB 커넥션 사용량 등을 실시간 그래프로 볼 수 있습니다.
8. 로그 + 모니터링 통합 시나리오
가장 이상적인 구성은 다음과 같습니다.
[Application] → Logback (TraceID 포함)
↓
[Zipkin/Elastic APM] → 트레이스 추적
↓
[Prometheus/Grafana] → 시스템 메트릭 시각화
💡 핵심 요약:
- 로그로 “무엇이 발생했는가”를 보고,
- APM으로 “어디서 느려졌는가”를 확인하며,
- 메트릭으로 “얼마나 안정적인가”를 측정합니다.
이 세 가지를 결합하면 운영 효율이 획기적으로 높아집니다.
9. 운영 시 자주 발생하는 문제와 점검 포인트
① 로그 누락
Trace ID가 누락되면 요청 전체를 연결할 수 없습니다.
→ 필터 레벨에서 MDC 초기화 확인 필요
② 샘플링 확률
APM은 모든 요청을 추적하지 않습니다.
Spring Sleuth의 sampler.probability를 조정해 필요 시 1.0(100%)로 설정해야 합니다.
③ 스토리지 과부하
모든 로그와 트레이스를 장기간 저장하면 디스크가 빠르게 가득 찹니다.
→ APM 서버에 데이터 보존 주기(retention) 설정을 꼭 해야 합니다.
10. 모니터링을 문화로 만들기
로그와 APM은 단순한 “도구”가 아니라, 팀의 개발 문화를 바꾸는 “습관”입니다.
에러가 발생했을 때 “로그를 보여줘”라고 말할 수 있고, 성능이 느릴 때 “그래프를 확인하자”라고 말할 수 있다면, 그 팀은 이미 성숙한 운영 문화를 가진 것입니다.
마무리
API 로그 추적과 APM은 개발 이후의 “운영”을 완성시킵니다.
문제를 감으로 찾는 시대는 끝났습니다. 이제는 데이터를 보고 판단해야 합니다.
오늘부터는 로그, 트레이스, 메트릭 세 가지 눈으로 여러분의 서버를 관찰해 보세요.
다음 시리즈에서는 “운영 자동화 — 배포와 로그를 하나로 묶는 DevOps 환경 만들기”를 다룰 예정입니다.
이제 진짜 “지속 가능한 서버 운영”으로 넘어가 봅시다.
'Database & Storage' 카테고리의 다른 글
| 오라클 DB를 PostgreSQL로 마이그레이션하는 절차: 무중단 전환까지 실무 체크리스트 (0) | 2025.12.20 |
|---|---|
| 트랜잭션 잠금(Lock) 완전 정복: Deadlock 재현·원인 분석·해결 전략 실무 가이드 (0) | 2025.12.03 |
| JDBC 커넥션 풀(Connection Pool) 이해하기 — HikariCP 실무 설정 가이드 (0) | 2025.11.17 |
| SQL 튜닝 입문 — 실행계획(EXPLAIN)으로 성능 분석하기 실무 가이드 (1) | 2025.11.16 |
| 개발자가 자주 잊어버리는 SQL 기본 명령어 7가지 (JOIN, GROUP BY 실습) (0) | 2025.11.10 |



